Chromium browsers periodically serialise the state of open tabs to support crash recovery and session restoration. Files are written at intervals and at browser close, using Snappy compression and Protocol Buffer serialisation. Serialised state can include the URL, page title, and cached page content. For an AI tool session open at the time of serialisation, the captured tab state may include conversation content displayed in the browser at that moment. These files persist until a new browser session initialises successfully.
Captures AI tool session content at the time of browser close, independent of the History database and IndexedDB artifacts. Provides a corroborating record where other artifacts have been cleared.
The three artifact categories are created and maintained independently. Clearing browser history affects the SQLite database but not IndexedDB or session files. Deleting a conversation within the application affects the IndexedDB logical view but not the underlying log content, and does not affect session files. Full removal of evidence of an AI tool session requires deliberate, simultaneous clearing of all three artifact types — an action that does not occur through normal user behaviour or standard browser hygiene.
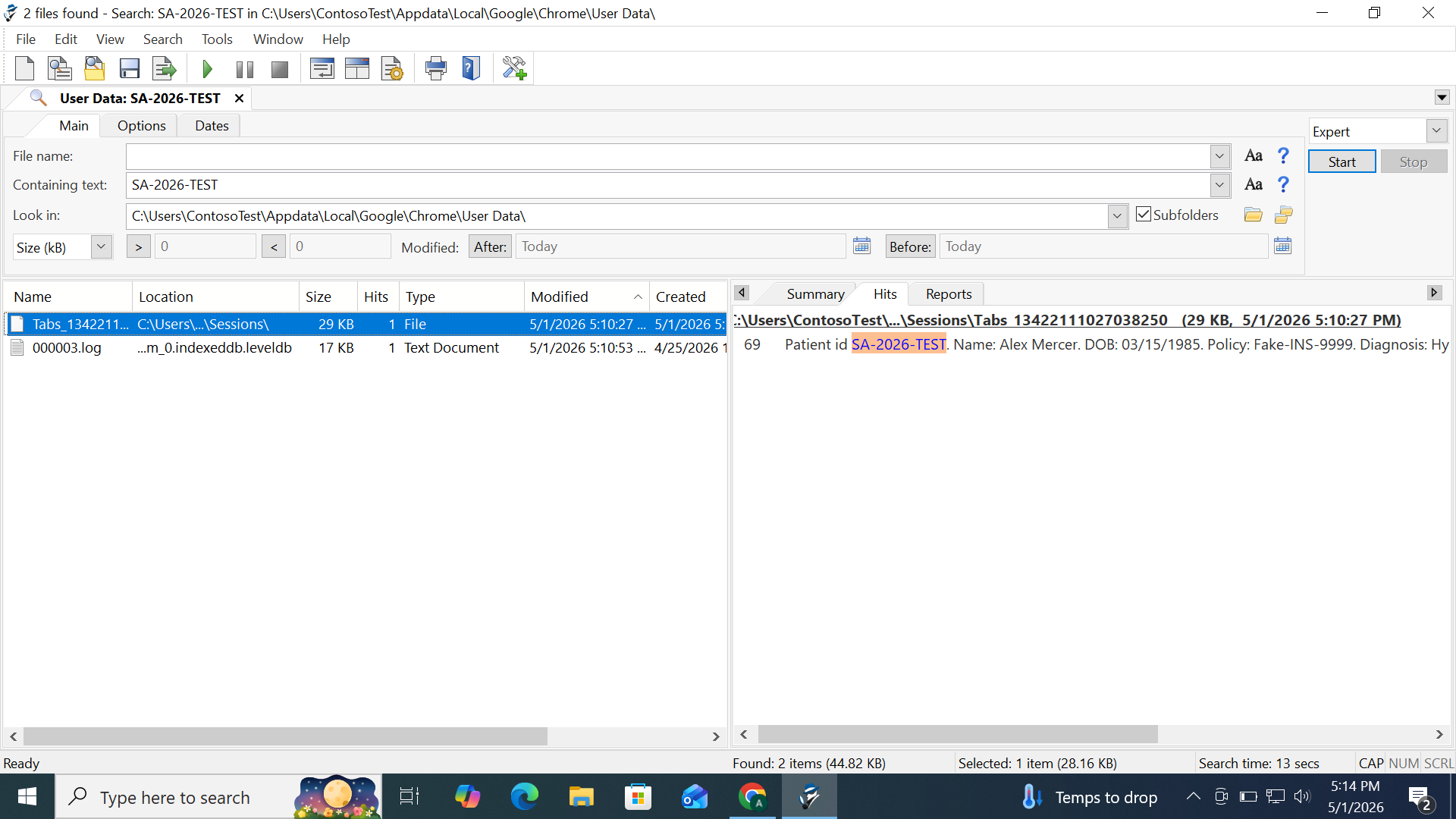
To validate the persistence behaviour described in Section 3, a controlled test was conducted. A unique synthetic patient record was submitted within a ChatGPT session in Google Chrome version 147.0.7727.137 (Official Build, 64-bit) on Windows 10, on 1 May 2026. The record used a fabricated patient ID (SA-2026-TEST) with a constructed name, date of birth, insurance number, and partial diagnosis — structured to resemble real PHI. The conversation was then deleted through the standard ChatGPT interface.
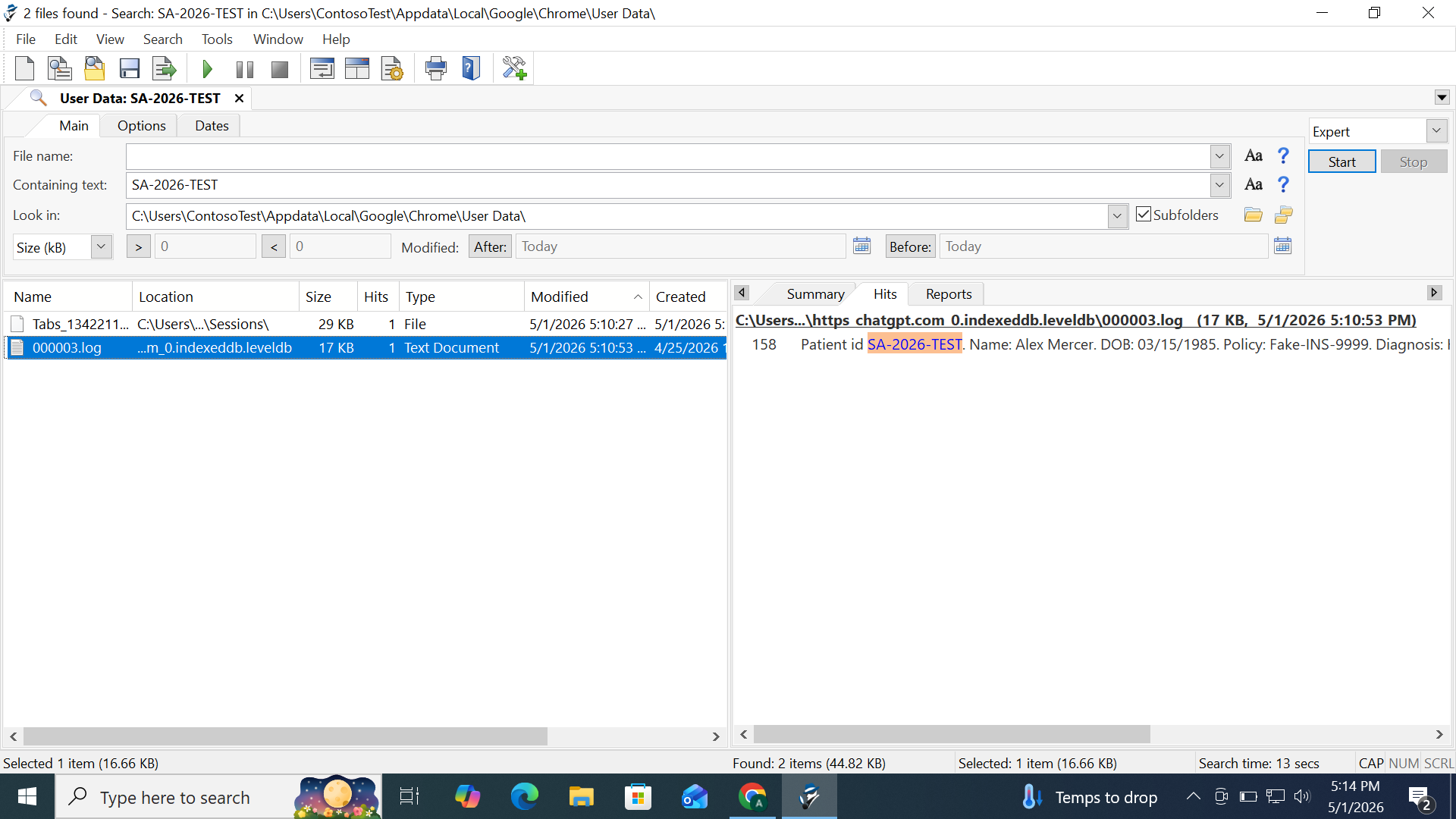
Following the deletion, the IndexedDB LevelDB directory was examined using a standard text editor. The test string was recovered from the 000003.log file at line 158 as readable text — the complete fabricated record intact: "Patient id SA-2026-TEST. Name: Alex Mercer. DOB: 03/15/1985. Policy: Fake-INS-9999. Diagnosis: Hy[pertension]." A corroborating occurrence was found independently in the Chrome session restore file Tabs_13422111027038250 at line 69. File metadata in Figure 2 confirms 000003.log was created on 25 April 2026 — six days before this test — showing the log accumulates data across multiple sessions.